

Rick Guyton
-
Posts
628 -
Joined
-
Days Won
41
Content Type
Profiles
Forums
Resource Library: Monster UI Apps for KAZOO
Events
Downloads
Posts posted by Rick Guyton
-
-
On 8/29/2020 at 10:04 PM, esoare said:
@Rick Guyton I know I’m resurrecting this post, but did you have a solution working???
Is it possible with a few API Tweaks?
I do have a few clients with CallThru.us that wondered about transferring.
esoare
Indeed I did get it working. Requires API though
-
14 hours ago, FASTDEVICE said:
I wasn't thinking real-time reporting but an account (or several for that matter) can generate a lot of messages to capture. Kafka appears to be a good way to continually capture the websocket data and generate reports later. Here is a guide for developing a Kafka connector. https://docs.confluent.io/current/connect/devguide.html
I mean, it would be cool to use it and gain familiarity with it. Maybe someone who knows Kafka can fork my project or use bits and pieces of it to make the connectors? I personally have 0 experience with it, so I couldn't say if it's even possible or if the tech is a good fit or not. From what I've heard, it's more for creating full pub/sub micro-services architectures. Much like how 2600hz uses RabbitMq. And that's a bit overkill for my purposes. I'm currently using this to gather events for all of my sub accounts. Extrapolating from that, I think this can easily accommodate 15k+ devices. More if you drop the subscriptions I have in there for qubicle. And, if you have that many devices, you should probably be in private cloud or global infrastructure where you can listen directly to RabbitMq instead of using websockets.
-
4 minutes ago, FASTDEVICE said:
@Rick Guyton have you considered using https://kafka.apache.org/ to store the data?
Yea, it's mentioned on the git actually. For people familiar with Kafka administration I'm sure it's a great fit. I'm interested in generating reports on a daily basis/weekly/monthly basis. If I were doing realtime, that'd be the ticket. But, I'm not sure what it offers otherwise to balance out the headache of another component to learn and admin.
-
Hello all! So, I thought I'd share some progress I've made on an app that connects to 2600hz websockets, listens for and saves events that come across. Then stores those files on backblaze for later processing. Today, I can only give you the 10,000 foot view on how it works and basic instructions on getting it going. I'll be adding another agent later that'll commit the events to a MySQL DB and do some processing on them to make them user readable. If you want to join in the fun though, you might want to get this agent up and running now so you can start gathering the data.
Repo: https://github.com/wildernesstechie/socketsink
10,000 foot view:
2 VPS machines run sink.py - These agents connect to your 2600hz cluster and record the events coming off of it to memory. Then, after 30 minutes the agent terminates, saving the events to a gzipped file and uploads them to backblaze
1 VPS running dbupload.py - This agent collects files from the unprocessed folder on backblaze, and commits them to a MySql database. A series of SQL statements are run to transform the raw events into more friendly data like hold time, park time, ringing time, missed, answered, ect.
1 VPS running a WebGUI - You will be on your own for this one. I'm using Databik for this. But, it's not free or open source, so I can't give it out to you all.
Basic Install Insructions:
Install python3.6+
clone the repo
setup a venv
pip the required packages (websocket-client, kazoo-sdk, b2sdk, mysql-connector-python)
Get yourself a backblaze b2 account and setup API keys for it
go into sink_settings.py and put your backblaze API key and id in
name your unprocessed folder (it can be anything)
put your account ID where it says 'KazooAccountIdHere' and your API key where it days 'ApiKeyHere' (sorry, only API keys work ATM)
If you aren't on hosted, you'll need to update your api base and webhook base URLs.
change to another ca bundle if you'd like.
The setup cron to run the agent every 0 and 30 minutes
Rinse, repeat on a second VPS except cron every 15 and 45 minutes.
Sit back and watch the data flow into your backblaze! I'll be back soon with an agent that imports to a DB. (It's already done, just needs some cleanup)
Merry Gift Giving Holiday Of Your Choosing and New Year!!!
")
-
So, the device naming is very strange. Is there any way to control that? Everything else is AMAZING. So easy to onboard now.
BTW, for anyone else using this, you can avoid having to confirm account rate increases by including the following JSON in your device/user. Obviously KNOW what your charges are and be ok with them auto-adding... You can also add caller ID info this way. Or add custom hold music on a per device level. Really anything. So nice...
{ "accept_charges": "true" } -
44 minutes ago, esoare said:
Next time @Karl Stallknecht (I know there won't be one though!
") ) send over a computer/box that has your remote access software + Ping plotter. Have them plug it in to their network. And then you can access the firewall programming through there. + See if connectivity to your IP's works without having to much problems.
) send over a computer/box that has your remote access software + Ping plotter. Have them plug it in to their network. And then you can access the firewall programming through there. + See if connectivity to your IP's works without having to much problems.
Also you could Angry IP scan their network, and then ARP -a to get the MAC address + IP addresses of the phones (assuming the OUI MAC you know)
Then script a login/reboot of the phones.
This post was REAL EASY to type, I'm sure it would still be a headache to actually do though!! (do they call that Sunday night quarterbacking?)
esoare
Few things, FYI Macs and local IPs for phone are available in the debugging app. No need to broadcast scan and ARP. I use this all the time to access phone WebUI while remoting into a client PC. BTW simple-help.com is a great cost effective self hosted remote access service. Also, provisioner can reboot phones easily.
The real issue with shipping routers is you have to be 100% right or you are screwed. Also, sometimes you need to setup PPPoE bridging to avoid double NAT. It’s a mess, if you are going to offer a router you need someone onsite.
-
A lot of what @Karl Stallknecht is saying is very true. At the end of the day you need three things. A good LAN, solid connectivity and sufficient bandwidth.
A Good LAN:
Well, this is 50% of the battle TBH. At the end of the day if the LAN sucks, so will the phones. Grab a VLAN if you can get it. (remarkably hard with many IT people for some reason) But, more than anything you need good IT. If you are targeting SMBs that means finding local IT folks or doing the IT for them. (I think Karl does his customer's IT) Good IT folks will usually be comfrotable with Cisco (not Meraki, but Cisco IOS), mikrotik, palo alto or juniper equipment. All they REALLY need to know is basics like jitter, packet loss, latency, and VLANing. But, most people who are proficient in this stuff aren't using netgear.
Solid Connectivity:
We use PingPlotter extensivly for this. I like to run continuous pings to a couple of the phones, the router, cable modem (192.168.100.1 typically), ISP gateway, 1.0.0.1, 8.8.8.8 and 4.2.2.2. This will give you a VERY accurate picture of jitter, PL, latency OVER TIME. And, tell you where it's starting. For instance if you are getting packet loss to the phones, there's LAN issues. To the router, LAN issues or bad router. To the modem bad modem. To the GW, bad circuit. GW ok, but others bad, peering issues with ISP. I'll roll this in advance if I'm able and get these issues resolved before deploying if I can.
Bandwidth:
Nope, 1.5Mbps ADSL isn't going to cut it... There's two ways to handle this. Either have them buy way more than they'll ever use (most people do this) or setup bandwidth management. I use Mikrotik routers personally wherever I can to do the latter.
So, to your question on how to prevent these issues, figure out a way to cover the above bases. Top of the list should be partnering with good IT folks.
To your question about how does everyone else do it? Well... Most go Karl's route and do the IT too. Or they don't mess with it. They sell to everyone and take the 80%. The 20% will get tech support that basically just points the finger at IT (I mean, they aren't wrong really). The vast majority or SMBs, especially with the rise of cloud services, don't even have any IT support AT ALL so they will deal with the occasional bad quality or move on to a land line provider. The remainder will blame their IT folks until they figure it out or do the same.
-
5 hours ago, Rick Guyton said:
Ugh, just in case anyone is following along... from_tag and to_tag eventually stay the same. It differs between hold/unhold #1 and hold/unhold #2. But, not thereafter. I'll be using both msg_id and timestamp to de-dup with. This leaves open the possibility that if someone managed to hold/unhold/hold again within 1 second that it'd throw off my stats. But, I feel like that'd be getting pretty edge case. I think AQMP had internal IDs it'd be nice to get at least a hash of AQMP's internal ID to de-dup with. But, this is the best there is for the moment as far as I can see.
Ok, last update and I'm leaving this be. The timestamp in the msg_id is down to the microsecond. So, I really don't need the seperate timestamp field on top of it. Messages can be de-duped with routing key + msg_id
-
21 minutes ago, Rick Guyton said:
Awesome as always @mc_ thanks! I'm going to concat all the things!!!
Ugh, just in case anyone is following along... from_tag and to_tag eventually stay the same. It differs between hold/unhold #1 and hold/unhold #2. But, not thereafter. I'll be using both msg_id and timestamp to de-dup with. This leaves open the possibility that if someone managed to hold/unhold/hold again within 1 second that it'd throw off my stats. But, I feel like that'd be getting pretty edge case. I think AQMP had internal IDs it'd be nice to get at least a hash of AQMP's internal ID to de-dup with. But, this is the best there is for the moment as far as I can see.
-
13 minutes ago, mc_ said:
This guy's blog is great in general for SIP stuff but specifically https://andrewjprokop.wordpress.com/2013/09/23/lets-play-sip-tag/
Awesome as always @mc_ thanks! I'm going to concat all the things!!!
-
Hey @mc_, do you know what "from_tag" is? This also seems to be unique across different hold events.
Also, seems like you are right, the msg_id does appear to be a timestamp
-
5 minutes ago, FASTDEVICE said:
Are you building a WS client in python? If so, is it standalone? We use Laravel/ PHP for our app development and Lumen for microservices.
I've got an agent in python that connects, subscribes to one or more accounts (and sub-accounts), records events and dumps them out to a file. It then uploads to backblaze storage for processing by another agent. I'll be open sourcing that part for sure most likely before the end of the year. If you could use that, I'd hate for you to duplicate your efforts.
-
2 minutes ago, FASTDEVICE said:
I'm trying to confirm that physical phone holds are creating hold events in websockets. There is no equivalent in Webhooks so I need to move to Websockets. I was planning to test it out over the weekend and your question seemed very timely. Thanks for confirming!
NP, if you haven't started on the websocket code code yet and python is acceptable to you, you might want to wait a bit before diving in. 😉
-
11 minutes ago, FASTDEVICE said:
@Rick Guyton was that event initiated by pressing the hold button on a device i.e. Yealink/ Polycom IP phone, or programmatically from the Operator Console Pro UI? I'm trying to detect when a user places a caller on hold from the IP phone directly.
So, you are listening on the AQMP. So regardless of the origin, it should come up. Are you looking to verify that this is the case? Or are you trying to differentiate between hold on Op Console vs physical phone holds?
EDIT: my example was done on a physical phone
-
Just now, mc_ said:
I believe msg_id for call events is the timestamp from FreeSWITCH, at least in 4.3. So presumably msg_id + event_name should be "unique"?
I'll concat msg_id and the routing key just to be safe. That'll do it I think. Thanks a bunch @mc_!
-
@FASTDEVICE Neither? AFAIK connecting to WS is equivalent to listening to the AQMP. So effectively you are seeing ecallmgr internally reporting to kazoo apps that a hold event has occurred after freeswitch told it so. I'm not 100% sure about that TBH. But, here's an example of a hold straight off the wire if it helps (censored like crazy obviously)
{"action": "event", "subscribed_key": "call.*.*", "subscription_key": "call.MY_ACCOUNT_ID_HERE.CHANNEL_HOLD.*", "name": "CHANNEL_HOLD", "routing_key": "call.MY_ACCOUNT_ID_HERE.CHANNEL_HOLD.CALL_ID_HERE", "data": {"to_tag": "NOT_SURE_IF_THIS_IS_SENSITIVE", "timestamp": 63743922729, "switch_url": "sip:mod_sofia@SOME_IP:11000", "switch_uri": "sip:SOME_IP:11000", "switch_nodename": "freeswitch@fs003.ord.p.zswitch.net", "switch_hostname": "fs003.ord.p.zswitch.net", "presence_id": "MY_EXT@MY_REALM", "other_leg_direction": "inbound", "other_leg_destination_number": "+MY_PHONE_NUM", "other_leg_caller_id_number": "+MY_CELL_PHONE_NUM", "other_leg_caller_id_name": "Rich Guyton Iii", "other_leg_call_id": "OTHER_CALL_LED_ID", "media_server": "fs003.ord.p.zswitch.net", "from_tag": "NOT_SURE_IF_THIS_IS_SENSITIVE", "disposition": "ANSWER", "custom_sip_headers": {"x_kazoo_invite_format": "contact", "x_kazoo_aor": "sip:MY_USER_NAME@MY_REALM"}, "custom_channel_vars": {"account_id": "MY_ACCOUNT_ID_HERE", "authorizing_id": "NOT_SURE_IF_THIS_IS_SENSITIVE", "authorizing_type": "device", "bridge_id": "OTHER_CALL_LED_ID", "call_interaction_id": "INTERACTION_ID", "channel_authorized": "true", "ecallmgr_node": "ecallmgr@apps002.ord.p.zswitch.net", "global_resource": "false", "inception": "+MY_PHONE_NUM@SOME_IP", "owner_id": "MY_OWNER_ID", "realm": "MY_REALM", "username": "MY_USER_NAME"}, "custom_application_vars": {}, "channel_state": "EXCHANGE_MEDIA", "channel_name": "sofia/sipinterface_1/MY_USER_NAME@MY_REALM", "channel_created_time": 1576703524752278, "channel_call_state": "HELD", "caller_id_number": "+MY_CELL_PHONE_NUM", "caller_id_name": "CleaRing - Rich Guyton Iii", "callee_id_number": "+MY_PHONE_NUM", "callee_id_name": "CleaRing", "call_direction": "outbound", "call_id": "CALL_ID_HERE", "msg_id": "NOT_SURE_IF_THIS_IS_SENSITIVE", "event_name": "CHANNEL_HOLD", "event_category": "call_event", "app_version": "4.0.0", "app_name": "ecallmgr"}}
-
I'm developing a reporting app and as part of it, I have two "agent" servers connecting to my Kazoo API using websockets and listening to events. They each listen for 30 minutes before closing and relaunching. "agent 1" starts on every 0 and 30 minute and "agent 2" starts on every 15 and 45 minute of the hour. This way, I have some redundancy. This obviously leaves me with duplicate messages though and I need a way to de-dup them. I have been using the routing key and this worked really well until I tried to do reporting on call hold time when the calls were held/unheld multiple times in a session. I've looked further into it and it seems like the key I should have been pulling is msg_id. But, before I invest the time to re-write my code to use this key to de-dup my messages, I want to be sure this would work as expected.
Where you at @mc_? 😀
-
5 minutes ago, Karl Stallknecht said:
This is awesome!! Thanks!! I originally setup using root access as well because I couldn't figure out how to assign permissions properly (I tried and 2600hz wouldn't connect). I'll follow your advice to fix this!
Hey Karl! Glad I could help out! I had a feeling a few others probably just gave root creds...
-
Hi all!
I'm sure no one else has done this... But, to get things done, I initially setup a few customer accounts with root AWS access keys to get their call recording going. Needless to say, that's super dangerous. So, I recently invested the time to find the minimal possible permissions to provision an account with AWS. And I thought I might as well share. This assumes you will be assigning each customer a separate bucket. Technically, you could put all your clients into a single bucket. But, that makes the permissions much harder.
So, here's the step by step directions. They look really long, but it really is very easy, these are just very detailed instructions:
SETUP AN S3 BUCKET
1) Log into your AWS portal and access the S3 app
2) Click Create Bucket
3) Enter a new bucketname. Doesn't matter what it is, but write it down somewhere
4) US West (N. California) for your region
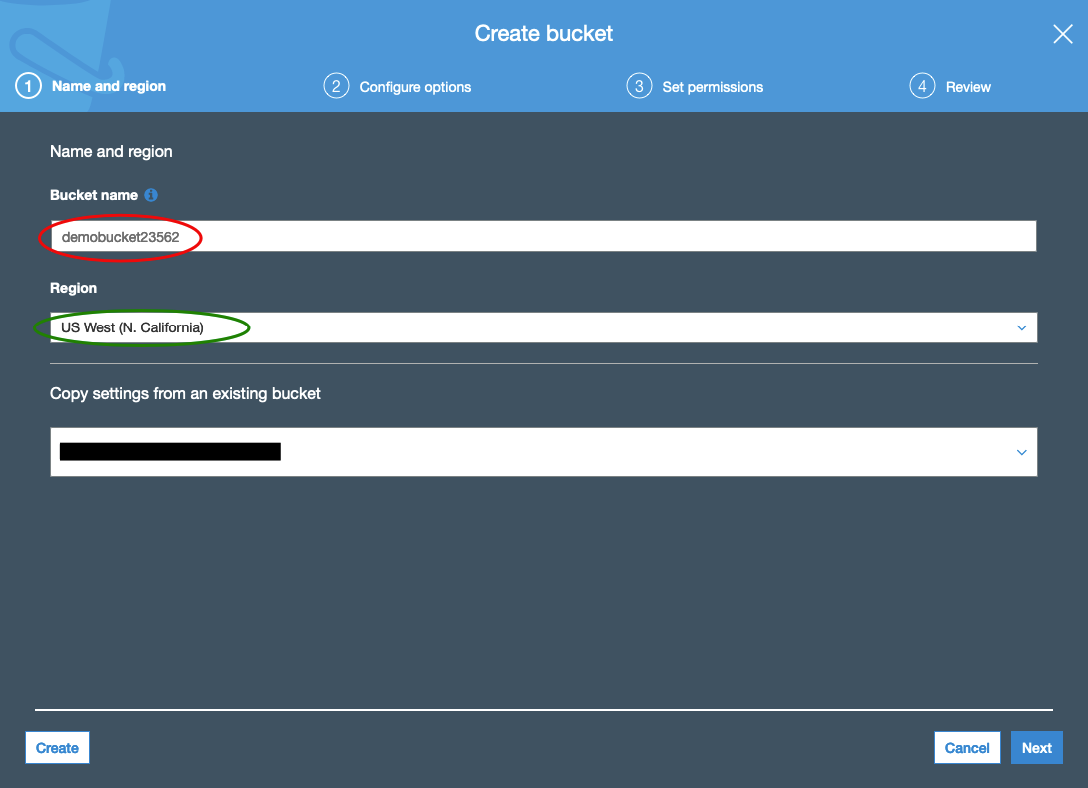
5) Next through the remaining panes and create the bucket. You should read through them and make sure that meet your needs. I especially recommend enabling the "Block ALL public access" option.
SETUP AN IAM USER
1) Access the IAM app
2) Click Add User
3) Enter your a new username
4) Check Programmatic access
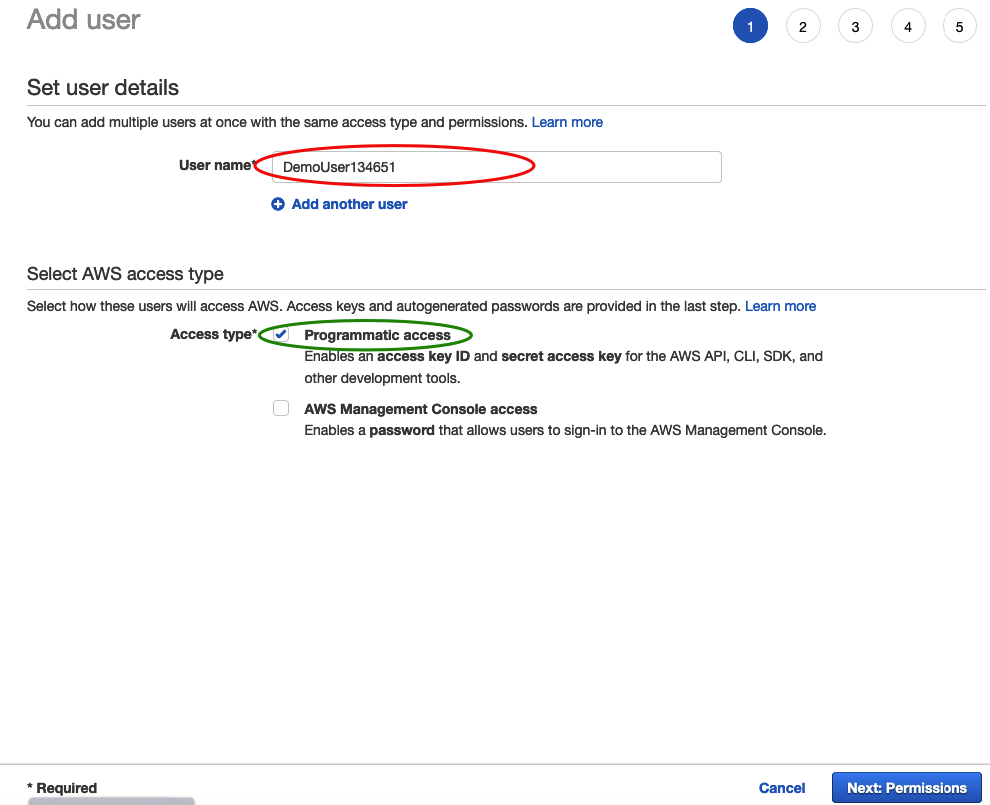
5) In the next pane, select Attach existing policies directly and then select create policy
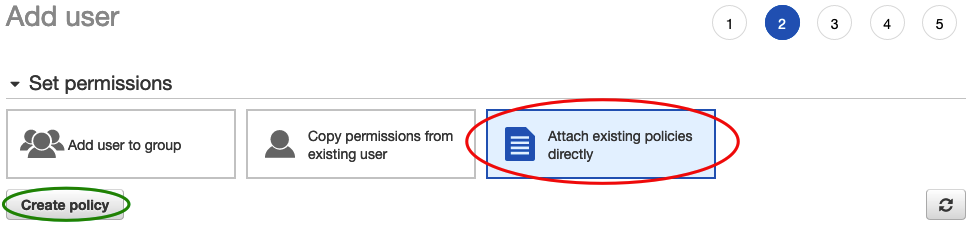
6) This will open a new tab for you to enter your policy into. Click the JSON tab and enter this and replace "BUCKET_NAME_HERE" with your bucket name from above. Then, click review policy.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:PutObject", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::BUCKET_NAME_HERE/*", "arn:aws:s3:::BUCKET_NAME_HERE" ] } ] }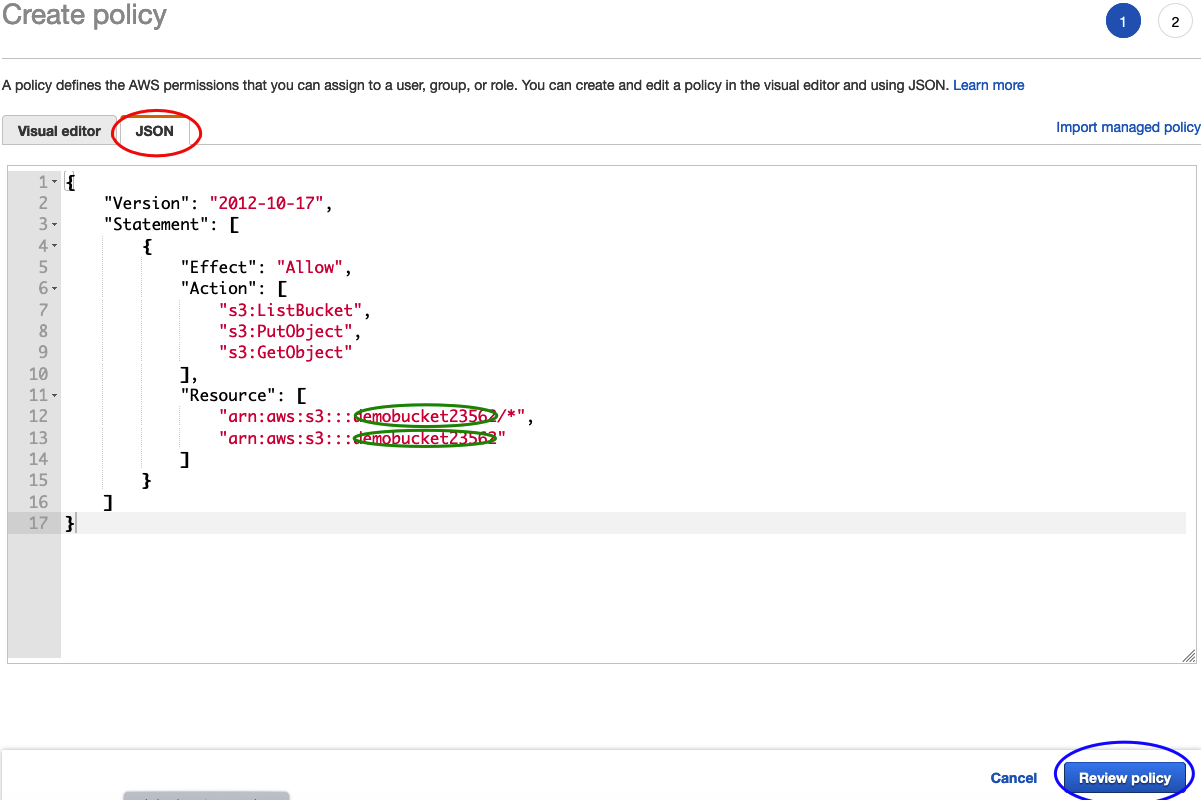
7) Name your policy and click create policy
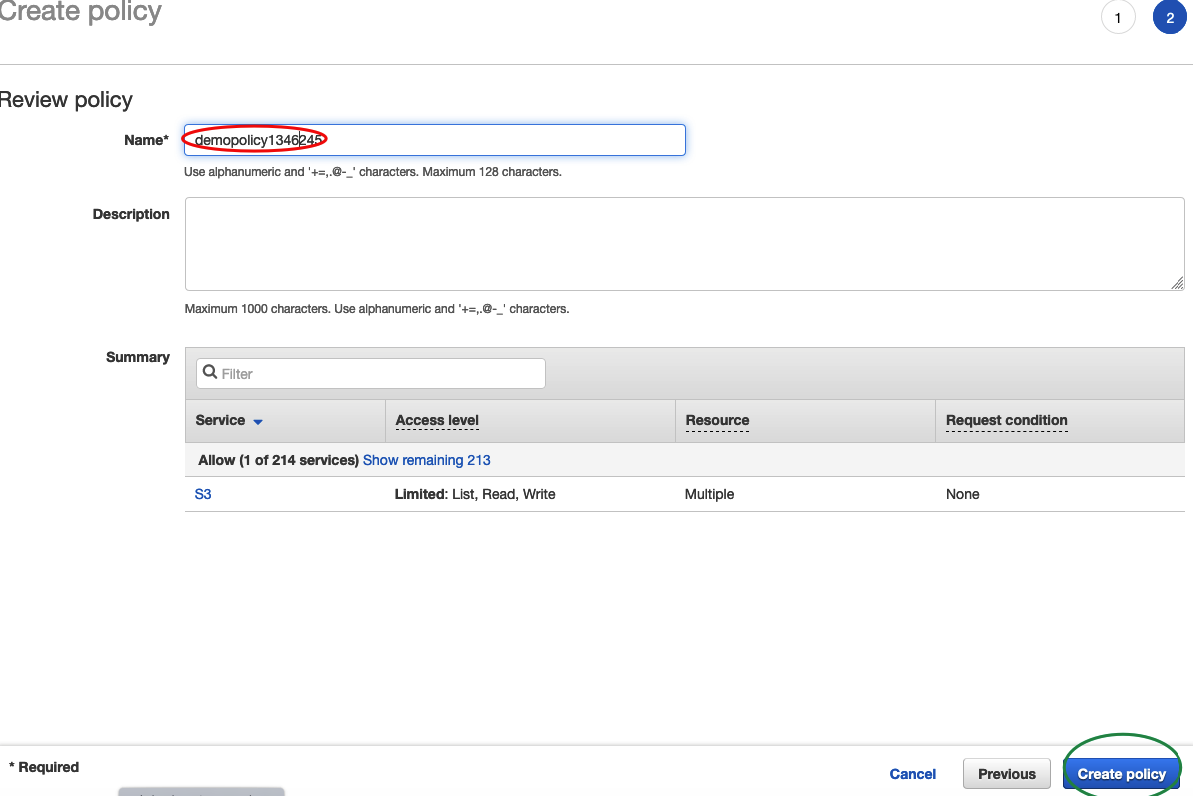
8 ) Back on you IAM tab, click refresh, enter the name of the policy in the search you assigned in step 7, check it and press next

9) The next two pages are for tagging and review, you can just leave them blank and click create user.
10) On the next page, you will get you access key and secret access key. SAVE THESE! You need them to input into your connector

11) Back in the main page for IAM, click Users, and click on your user account. Save the ARN shown
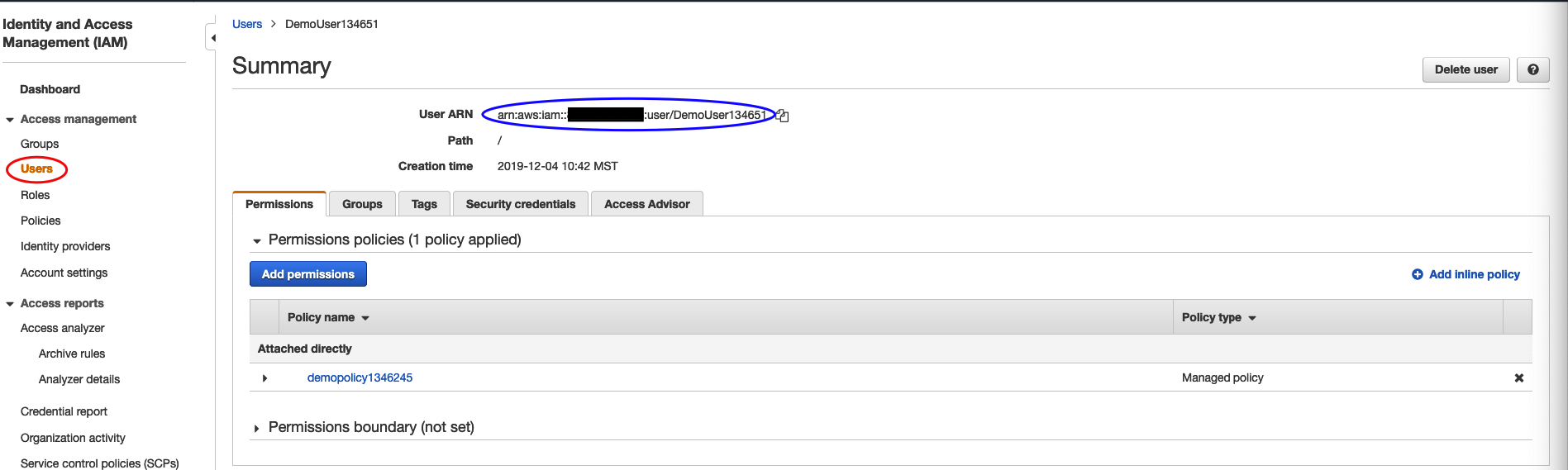
BUCKET POLICY
1) Go back into your S3 app and click on your bucket
2) Click permissions, then bucket policy and enter this JSON. Update your bucket name and ARN. Then save.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "ARN_FOR_IAM_USER_HERE" }, "Action": [ "s3:GetObject", "s3:ListBucket", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::BUCKET_NAME_HERE/*", "arn:aws:s3:::BUCKET_NAME_HERE" ] } ] }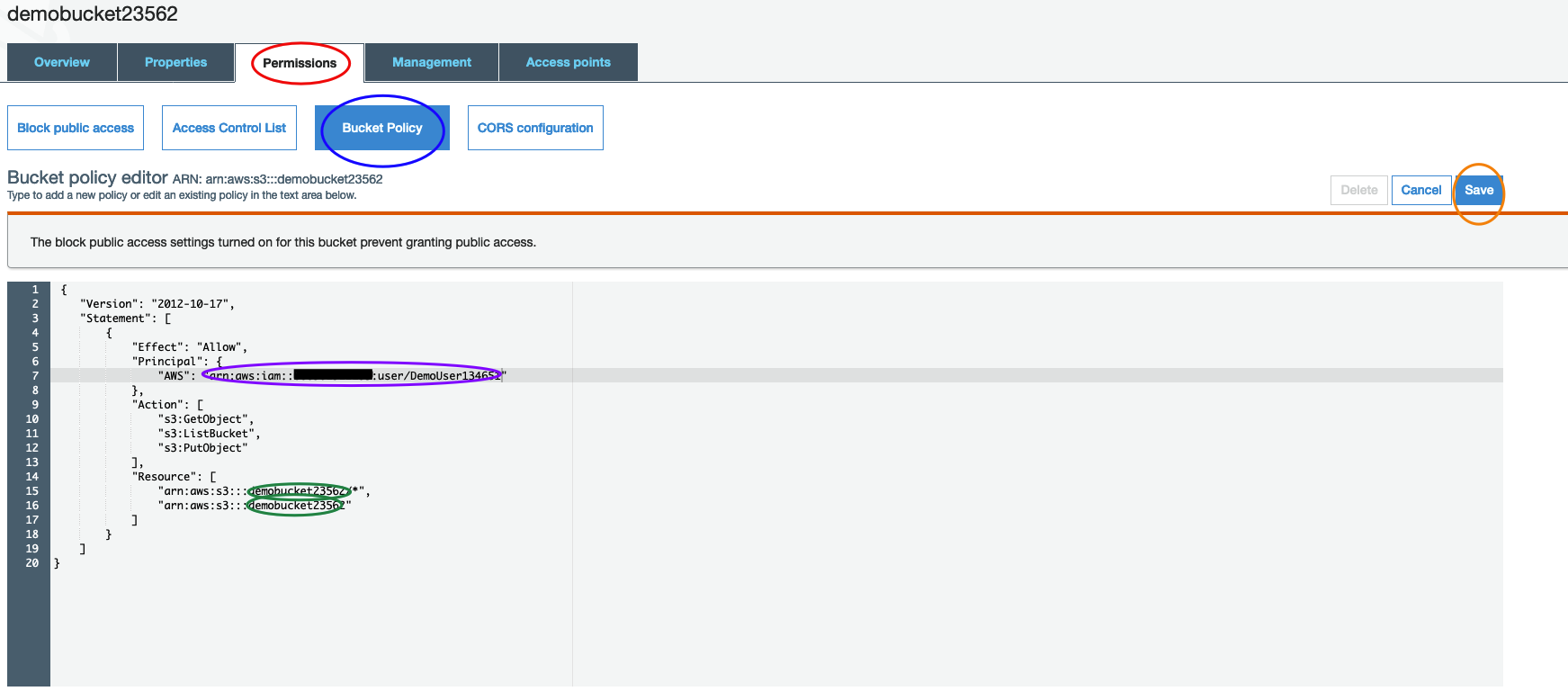
AWS APP In Kazoo
1) Now, just enter your AWS info as collected above. If you used the region I recommended above, your host is s3-us-west-1.amazonaws.com.
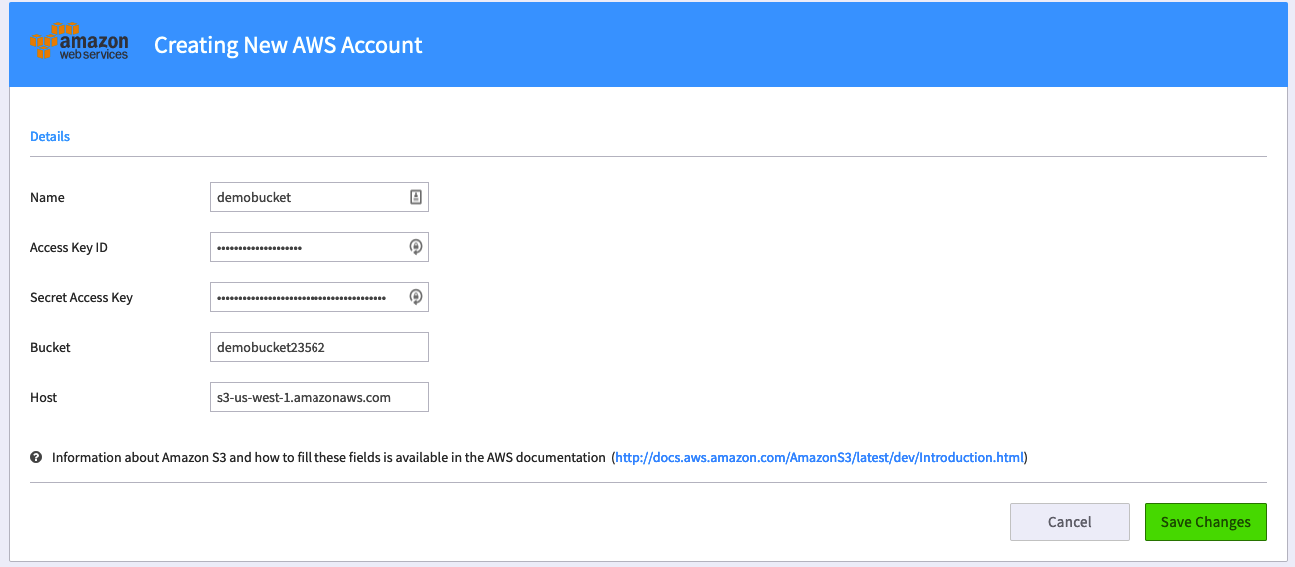
Thats it! If anyone has any feedback, I'd love to hear. I hope you all find it useful!
-
21 hours ago, Shabbir Tapal said:
Hey Darren,
Thanks for your response, yes you are right as we are using Comcast business as the provider, however is there a recommended Auto setting that would help prioritize Voice over Data?
Hi Shabbir,
In my experience it's really more about managing your bandwidth locally than relying on the ISP to handle it for you via QOS tagging. Basically what you do is self-restrict your bandwidth and then shape it. So, if you have a 25/5 connection and you tell the router to only ever use 24/4, you can control what comes into/out of the router first. QOS tagging is nice if your ISP supports it. So far, the only carrier that I've seen support it well is CenturyLink though. I've seen really great results using bandwidth management via PfSense, MikroTik and SonicWall systems. (Careful with sonicwall though, the old stuff HATES on SIP) I've had my IT partners implement Meraki and straight Cisco routers with great success as well. Though I've never personally set them up.
PfSense is probably the easiest IMO. They sell their own routers now and there's a step by step wizard to configuring them. Their entry price point prevents me from deploying them. I think their least expensive is over $500 last I checked and that's just too much for me to standardize on.
MikroTik is AMAZING. But... TBH they are a bit like drinking out of a firehose. A firehose with poor docs. Master them and the world of networking is your oyster though. They are no BS ISP grade hardware. And they have SoHo routers starting under $100 and nothing over $350 (except Cloud core and those are overkill for anything less than ISP/datacenter work). I have a script on here to help you get going, but it needs updates. Let me know if you are interested and I'll polish it up for you. Many of my IT partners can do just it all themselves now, so I haven't had the impetus to update it.
SonicWalls do this as well. But you should be aware that some of the older sonicwalls do terrible terrible things to SIP. New stuff seems pretty good, though I would recommend disabling SIP ALG on them.
Meraki are great and pretty easy to configure form what I've seen. But you pay for it on a subscription model. From what I understand if you stop paying the subscription, the router bricks. Youch... Not my style, but people have great success with them.
Cisco, well, there's a saying "Nobody gets fired for going with Cisco". And yea, they are the 10,000 pound gorilla, have crazy good name recognition and are rock solid. But, you will pay for that badge and for the consultant to configure it for you...
-
AFAIK, not without modify the source. BUT, you could do shoutcast instead. @FASTDEVICE has some really cool solutions for that if you are interested.
-
+1 just because I can't figure out how to follow a thread on my mobile phone without replying
-
9 minutes ago, Darren Schreiber said:
There are multiple scenarios here:
1) Shoutcast stream doesn't stream at all. Right now when we start playback of an audio file we wait for it to start which is confirmed by various events. These events never fire, so code doesn't advance.
2) FreeSWITCH itself is actually where the main issue is - it's default behavior is to either advance or hangup, depending on the situation, when you ask it to do something invalid like play a non-working stream. In addition, it's behavior halfway through a stream when a connection closes is to advance, which triggers events that cause us to think the call should advance, further gumming up the works.
3) Neither FreeSWITCH nor Kazoo have a concept of an alternate stream to play (even silence is a stream) so we'd have to somehow update the code to support that
4) You would likely have to make the failback strategy configurable, thus a GUI component. Not everyone will accept just "silence" as a failover strategy and will complain just as loudly here when their callers suddenly hear silence that it's broken/not usable.
All the above would of course have to be tested.
I suspect it'd be about 40-120 hours of work (one to three weeks of hacking on this basically), with knowledge required being a mix of C code and Erlang. Then about 20 hours to test each scenario. You also need to get the C code changes committed upstream to FS since we keep in sync with their branch now, so there's about 10-20 hours of "management" in there. So the entire thing is probably 80-200 hours. Assume $150/hour minimum for this skillset, it's a $12,000 - $24,000 request.
One way to fund this is we could get upfront commitments for people who want to use this. Let's say 10 resellers committed to pay for it for a year at $100/person/month, or up to two years to cover the higher end of the estimate. That would cover the cost.
Three thoughts.
First, yea that is 10,000x more difficult than I think most would think and I appreciate the time to explain why it isn't so.
Second, it's nice to hear a viable offer to the solution, I could care less personally about the shoutcast, so I'm not in. But, to put myself in those shoes, if it were the same cost for a resolution to the pivot issue, I would be.
Third, on #4 I think that decision should be left to those funding it if it drastically decreases the cost...
-
17 hours ago, FASTDEVICE said:
@esoare there is failover for Pivot.
Oh, really? How do you do that @FASTDEVICE? There's some things I'd like to do with pivot, but wont do it because I thought that wasn't the case and didn't want to risk it. I generally only use it now where it would be "acceptable" for the it to go down.
I don't have a horse in this race, but I do sure wish Kazoo would allow fail over to an internal resources for this stuff. Much the same way that voicemails will deposit into VM boxes if vm-to-email fails. I sure wish pivot could fail over to a default call flow, and for my friends who use it, shoutcast could just play silence instead of hanging up. At my own peril, how hard is it to catch any exception in the Shoutcast code block and simply play silence? I honestly don't know, one of these days I'll pick up erlang...
transfering mobile calls
in 2600Hz Mobile
Posted
@esoare sorry, I remember hearing specifically it doesn’t. But I know @Izabell balash would love to know more about the use cases for this!